

隱私保護數據生成
DeCloak 創新合成數據生成技術 – 就像真實數據一樣可分析且符合國際隱私保護法規 (如 GDPR、CPRA )
數據隱私的重要性
我們處在一個大數據時代,網路及個人數據急遽的增加中,也意味著有很多的客戶資料或個人訊息被網路服務公司或所屬企業所收集。然而,近年網路攻擊、企業內部資料被駭客竊取頻繁,並有機密或個資外洩事件屢見不鮮;因應全球個人隱私保護法規及制度的建立,各民間企業及政府組織也逐漸重視個人隱私的問題,並視為企業及政府內部重要且必要的存在。根據歐洲通用數據保護條例 (GDPR) 第26條,保證數據匿名且去識別化則可不受GDPR 的規範。
目前全球大約只有20%的人其個人資料受到隱私保護,在各國的立法與法規的極力推動下到2023年將達到75%,而有80%以上的公司將面臨至少一項以隱私為重點的數據保護法規,到2024年全球隱私計算市場支出將達到150億美元。帝濶智慧科技就是瞄準這樣龐大的市場,扎根台灣、布局全球,提供相關的隱私計算產品於擁有資料的個人及公司上。
我們開發了軟/硬體數據隱私處理技術,該軟/硬體通過使用隱私計算[如差分隱私(differential privacy)、聯邦式學習(federated learning)、同態加密(homomorphic encryption)等],搭配人工智慧模型來生成及分析具有隱私保證的合成數據。下面我們簡要介紹什麼是合成數據以及它與傳統數據保護方法的差異。
傳統數據隱私保護方法與缺點
假名化 (Pseudonymization)
保護個人隱私的原始方法之一是假名化。假名化是指將身份屬性的值重新命名 (如姓名、電話)。在下面的假名化數據集內,對姓名進行了重新標示。
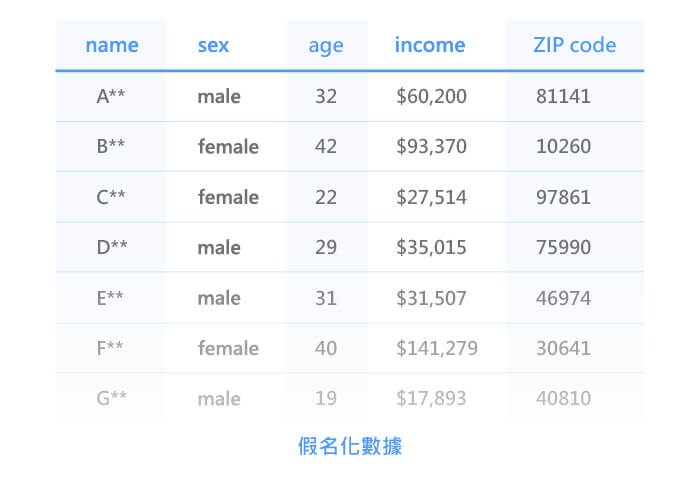
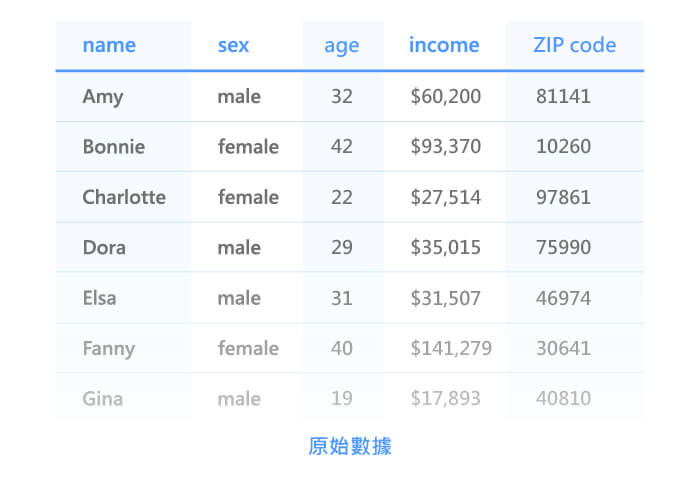
假名化數據的發布已被證明具有再識別的風險,因為它可以很容易地透過鏈結攻擊(linkage attack)來鏈結到其他數據集,經由各種間接識別符(quasi-identifier) (如Age、Sex、Income)以重新識別出個人。舉例一個經典案例,美國馬薩諸塞州發布了醫療患者數據庫(DB1),數據庫的內容去掉患者的姓名和地址,保留患者的{ ZIP code, Birthday, Sex, Diagnosis,… }資料。另一個可獲得的數據庫(DB2),是州選民的登記表,包括選民的{ ZIP code, Birthday, Sex, Name, Address,… }詳細個人資料。攻擊者將這兩組數據庫的同屬性段{ ZIP, Birthday, Sex }進行鏈結和匹配操作,可以還原出大部分選民的醫療健康資料(如以下圖所示),從而導致選民的醫療隱私數據被洩露。

圖:鏈結攻擊兩組數據庫,還原選民醫療健康資料
根據我們上面範例的假名化數據,假設該地區只有一名女性郵遞區號(ZIP code)為 10260。我們可以使用一些公共記錄來查詢此資料並將其鏈結到第二行 Age。通過結合這些公開資料,我們可以得出結論,此女性的年齡為 42歲。
K-匿名 (K-Anonymization)
另一種旨在對抗鏈結攻擊的方法是 K-匿名。這是通過概括和刪除可以重新識別個人數據記錄中的屬性來完成的,在下面的K-匿名數據,刪除了姓名。
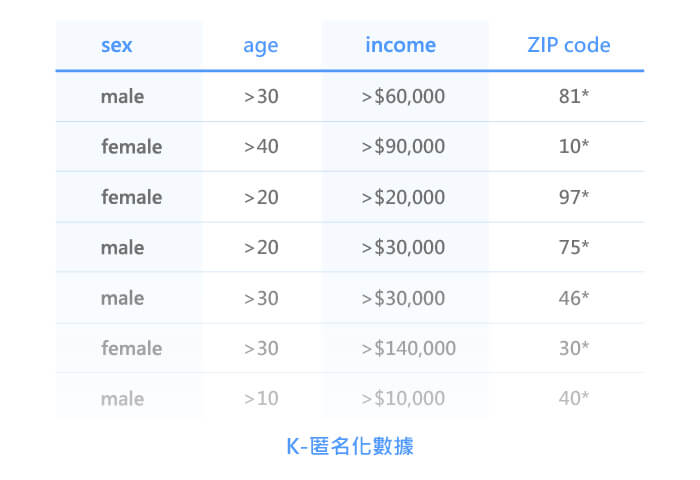
這種技術可以防止基於間接識別符(quasi-identifier)的外部數據記錄鏈結而造成重新識別的風險。然而,這種技術會損害原始數據的分析精準度,因為這些數據會被高度聚合或完全刪除。
這種方法的另一個問題是,如果敏感屬性是同質的(homogeneous)或具有偏態分佈(bias distribution),此種數據集會遭受同質化攻擊(homogeneity attack)或背景知識攻擊(background knowledge attack),攻擊者將能夠部分或完全重新識別個人而無法保障數據隱私。
回到我們的K-匿名數據範例,我們已經無法再透過郵遞區號(ZIP code)10260再識別到 Bonnie,因為她將會受到其他具有相似屬性的另一個人的保護(例如同樣 >40歲的女性但她的郵遞區號可能為 10369)。在這狀況下,Sex 這屬性仍然可能被鏈結攻擊,雖然我們可以通過屏蔽 Sex 屬性來防止這種情況發生,但這會導致該數據集的可用性急劇下降。
符合GDPR規範的合成數據
合成數據 (Synthetic Data)
合成數據是由演算法生成的數據,而不是基於真實的原始數據。合成數據能夠從數學或統計學上反映真實數據的特性或分布。在訓練 AI 模型方面,合成數據與基於實際物體、事件或人的數據一樣具有等價效用,甚至比真實數據更好。總體思路是合成數據由新數據點組成,而不僅僅是對現有數據集的修改。
DeCloak 生成的合成數據是保護隱私的合成數據,因可以以相同屬性但不同內容或是隨機亂數方式呈現,因為它帶有數據隱私保護保證並且被認為是完全匿名的。
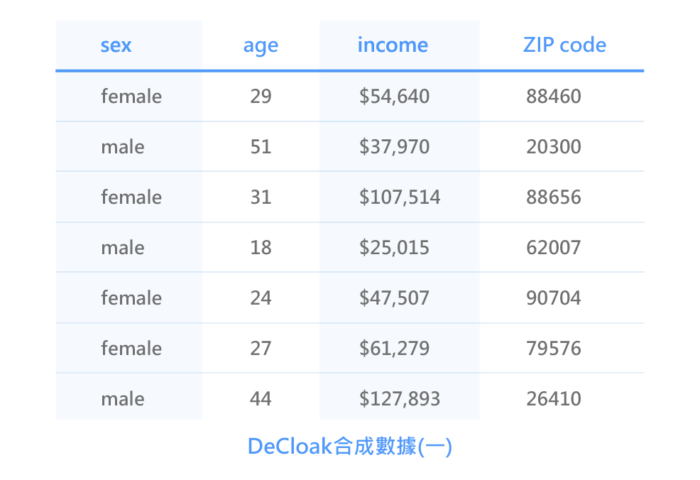
DeCloak合成數據樣態(一):相同屬性但不同內容的呈現。
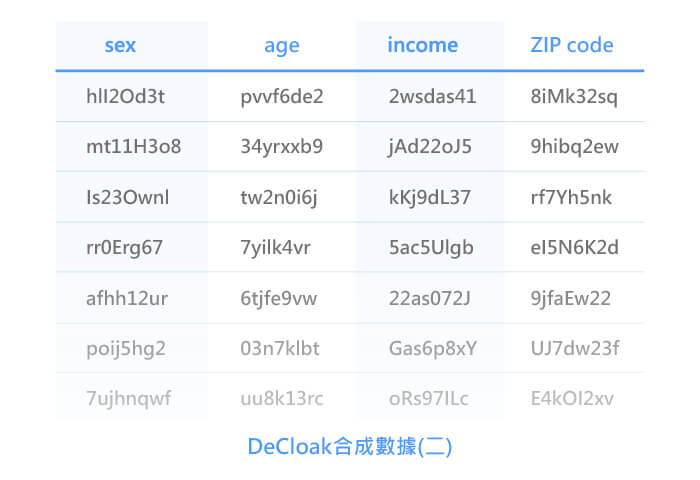
DeCloak合成數據樣態(二):相同屬性但隨機亂數的呈現。
合成數據就像原始數據一樣工作
合成數據生成實際上是一個非常複雜的技術過程,在該過程中DeCloak利用具有專利的隱私計算技術搭配密碼學與人工智慧模型生成新的合成數據集,這些數據集反映了原始數據的統計特性。
DeCloak生成的隱私保護合成數據具有以下屬性:
- 符合國際隱私保護法規範
- 保護個人隱私
- 數據具有匿名性
- 保留原始數據結構&統計屬性,可分析的數據
- 不可追蹤的數據,防止鏈結攻擊
DeCloak的創新專利技術,符合歐盟近年來制定的《一般資料保護規範》(General Data Protection Regulation, GDPR)以及美國的《加州隱私權利法》(California Privacy Rights Act, CPRA)中的匿名化及去識別化定義,形成非個人資料(non-personal data)之數據集。可以在不侵犯個人隱私的情況下,對數據進行匯整、分析以及運用;在有效保護個人隱私之下,企業可同時收集並分析有價值的用戶行為資訊。

