

Privacy-preserving Data Generation
DeCloak’s innovative synthetic data generation technology – as analyzable as real data and compliant with international privacy protection regulations (e.g. GDPR, CPRA)
The Importance of Data Privacy
We live in an era of big data. The rapid growth of Internet and personal data means that a lot of customer data or personal information are being collected by Internet service companies or their affiliated companies. However, in recent years, cyber-attacks and hacking incidents are frequent regarding personal information leakage. In response to above problems, establishment of regional and global personal privacy protection regulations are enacted, which leads enterprises and government organizations to pay more attention to the protection of personal privacy. According to Article 26 of the European General Data Protection Regulation (GDPR), guarantees of anonymity and de-identification of data are exempt from the GDPR. At present, only about 20% of people in the world have their personal data protected by privacy. Under the strong promotion of national legislation and regulations, it will reach 75% by 2023, and more than 80% of companies will face at least one privacy-focused privacy policy. Under data protection regulations, global privacy computing market spending will reach $15 billion by 2024. DeCloak aims for this privacy protecting market by providing relevant privacy computing products to individuals and companies with data. We have developed software and hardware data privacy processing technologies that uses privacy computing such as differential privacy, federated learning, homomorphic encryption and others, to incorporate with artificial intelligence models to generate and analyze synthetic data with privacy guarantees. Below we will briefly describe what synthetic data is and how it differs from traditional data protection methods.
Traditional Data Privacy Protection Methods and Shortcomings
Pseudonymization
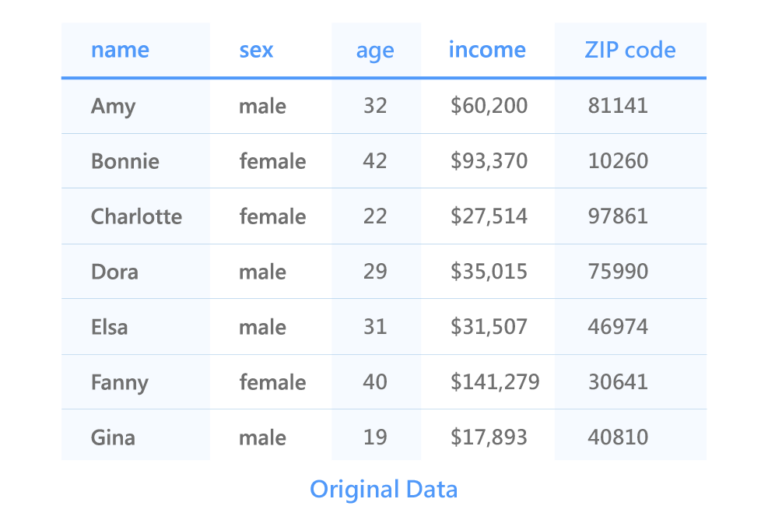
One of the original ways to protect personal privacy is pseudonymization. Pseudonymization refers to renaming the value of an identity attribute (eg, name, phone). In the pseudonymized dataset below, names are relabeled.
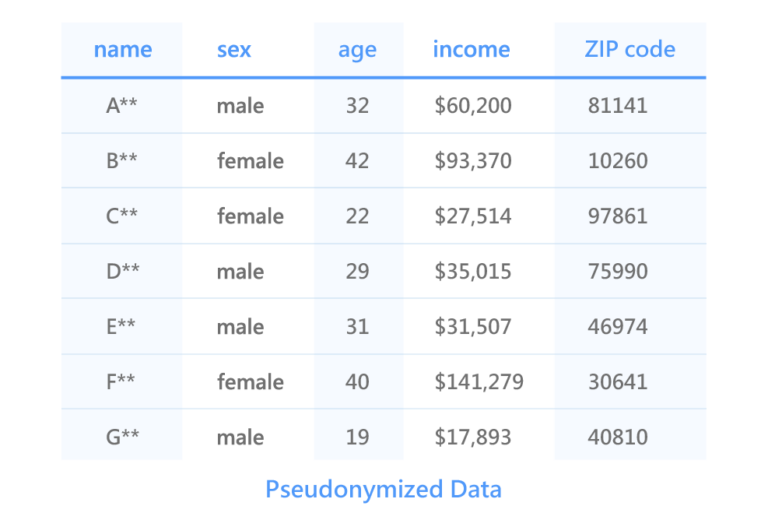
The release of pseudonymized data has been proven to carry a risk of re-identification, as it can easily be linked to other datasets through a linkage attack, via various quasi-identifiers (such as Age, Sex, Income) to re-identify individuals. As a classic case, the state of Massachusetts has released a medical patient database (DB1), which removed the patient names and addresses, and retained the patient’s {ZIP code, Birthday, Sex, Diagnosis,…} information. Another database available (DB2) is the state voter registration form, which includes the voter’s {ZIP code, Birthday, Sex, Name, Address,…} detailed profile. The attacker linked and matched the same attribute segments { ZIP, Birthday, Sex } of these two sets of databases, and restored the medical and health information of most voters (as shown in the following figure), resulting in the medical privacy data of voters were leaked.

Figure: Linkage attack on two sets of databases to restore voters’ medical and health data
Based on the pseudonymized data from our example above, let’s say there is only one woman in the area with a ZIP code (ZIP code) 10260. We can use some public records to query this profile and link it to the second row: Age. By combining these publicly available data, we can conclude that this woman is 42 years old.
K-Anonymization
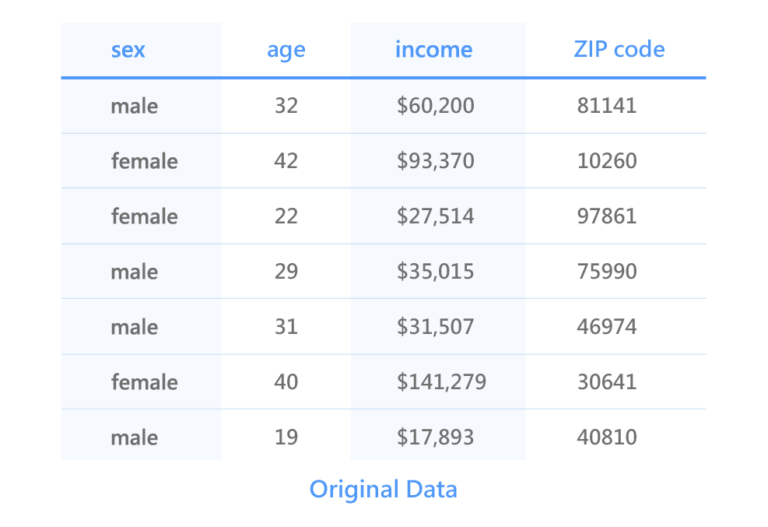
Another method aimed at combating chaining attacks is K-anonymity. This is done by summarizing and deleting attributes in the records of re-identifiable personal data, in the K-Anonymous Data below, with names removed.
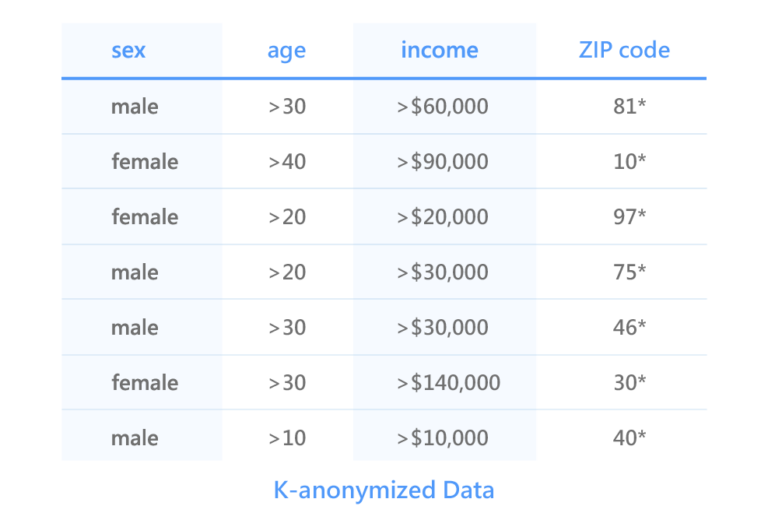
This technique prevents the risk of re-identification caused by the linking of external data records based on quasi-identifiers. However, this technique compromises the analytical precision of the raw data, which results data become highly aggregated or removed entirely.
Another problem with this approach is that if the sensitive attributes are homogeneous or have a skewed distribution, such datasets are subject to homogeneity attacks or background knowledge attacks; attackers will be able to partially or fully re-identify individuals without guaranteeing data privacy.
Going back to our K-anonymous data example above, we can no longer identify Bonnie by ZIP code (ZIP code) 10260 because she will be protected by another person with similar attributes (eg a female who is also >40 but Her postal code might be 10369). In this case, the Sex property can still be attacked by chaining, although we can prevent this by masking the Sex property, but this will lead to a sharp drop in the usability of the dataset.
Synthetic Data for GDPR Compliance
Synthetic data
Synthetic data is data generated by algorithms, not based on real raw data. Synthetic data can mathematically or statistically reflect the properties or distributions of real data. Synthetic data is as effective as, or even better than, data based on real objects, events, or people when it comes to training AI models. The general idea is that synthetic data consists of new data points, not just modifications to existing datasets. Synthetic data generated by DeCloak is privacy-preserving synthetic data, as it can be presented with the same attributes but different content or random numbers, because it comes with data privacy protection guarantees and is considered completely anonymous.
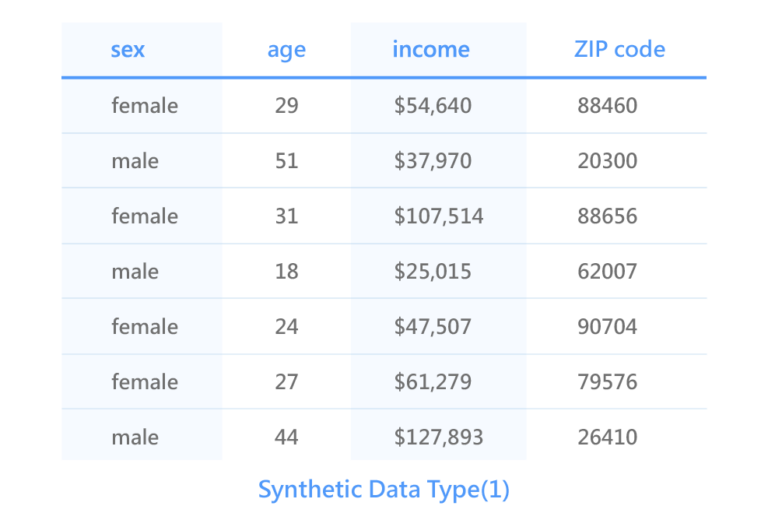
DeCloak’s Synthetic Data Type(1): The presentation of the same attributes but different content
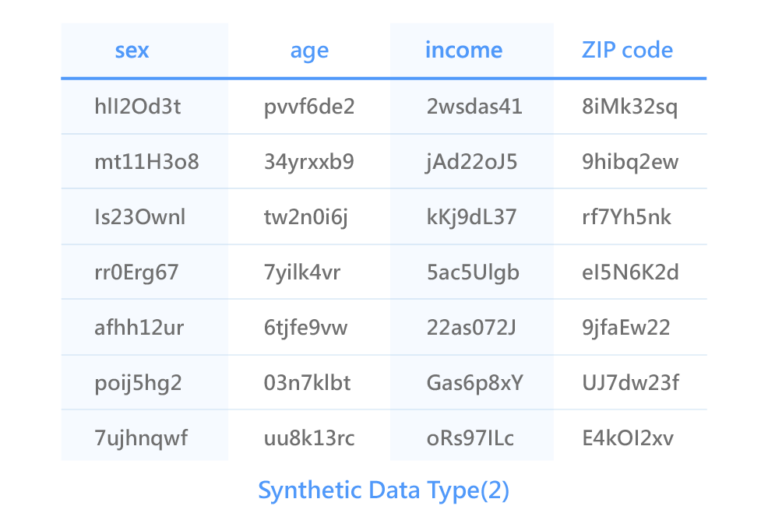
DeCloak’s Synthetic Data Type(2): The presentation of the same attributes but random numbers
Synthetic Data Works Just Like Raw Data
Synthetic data generation is actually a very complex technical process, in which DeCloak utilizes patented privacy computing technology with cryptography and artificial intelligence models to generate new synthetic datasets that reflect the statistical properties of the original data.
The privacy-preserving synthetic data generated by DeCloak has the following properties:
- Comply with international privacy protection laws and regulations
- Protect personal privacy
- Data is anonymous
- Retain original data structure & statistical properties, analyzable data
- Untraceable data to prevent linkage attacks
DeCloak’s innovative and patented technology can form a dataset of non-personal data which complies with the anonymization and de-identification requirement of the General Data Protection Regulation (GDPR) and the California Privacy Rights Act (CPRA). Data through DeCloak can be collected, analyzed and used without infringing on personal privacy. Under such effective protection of personal privacy, enterprises can simultaneously collect and analyze valuable user behavior information.

